Part A of this two part project shows what you can do utilizing a diffusion model. How to use it to restore noisy images, and generate new ones! To do this, we use the DeepFloyd IF diffusion model, a two stage model trained by Stability AI. Out of the box, it can be used to generate images of an oil painting of a snowy mountain village, a man wearing a hat, and a rocket ship as shown below:
Generated using 20 inference steps
Generated using 30 inference steps
(I used seed 180 for this project, but the seed wasn’t always set, so replicating exact images may not work perfectly)
It’s not very interesting to just generate the images, however; we want to understand how to generate them. Diffusion models predict the noise an image has, and aims to remove it..
In order to remove noise from an image, we must first
Original Image Noise Level 250 Noise Level 500 Noise Level 750
We then create a simple, more classical denoising technique of Gaussian blur filtering to see how good our model actually is.
Noise Level 250 Noise Level 500 Noise Level 750
This is ok, but very clearly not great. So now it’s time for our model
Noise Level 250 Noise Level 500 Noise Level 750
This does much better! Our resulting image appears to now resemble the campanile instead of confetti passed through YouTube’s compression algorithm. But we can still do better. This is predicting the total noise on our image and then removing all of it.
While we get decent looking results, our image becomes much better when we iteratively denoise it, and we can see the difference below
Original Iteratively Denoised One-Step Denoised Gaussian Blurred
Repeating the same process with completely random noise now allows us to generate completely new and spectacular images. We use the prompt "a high quality photo", and get these.
These look good, but not great. To fix some of the “nonsense” we see, we can use CFG. This process essentially nudges the images more into the imputed prompt, giving us these images.
I’m not entirely sure why they’re all faces. While developing and testing the code I was getting landscapes and other stuff, but not it’s only generating faces.
Now, let’s try to turn one image into another. Similar to before, we take an image, add noise to it, and then denoise. However, instead of trying to get back our original image, we add more and more noise, causing us to get a new image subtly based on our original.
i_start=1 i_start=3 i_start=5 i_start=7 i_start=10 i_start=20 Original
Now, let’s do the same but with images off the internet!
i_start=1 i_start=3 i_start=5 i_start=7 i_start=10 i_start=20 Original
And now using some that were very beautifully drawn by yours truly!
i_start=1 i_start=3 i_start=5 i_start=7 i_start=10 i_start=20 Original
To alter an image, we can also instead only edit a part of an image, and have it fit in with the rest.
Original Mask Hole to Fill Impainted Image
Now, we will do the same thing as SDEdit, but guide the projection with a text prompt. This is no longer pure "projection to the natural image manifold" but also adds control using language.
In this part, we are finally ready to implement Visual Anagrams and create optical illusions with diffusion models. In this part, we will create an image that looks like "an oil painting of people around a campfire", but when flipped upside down will reveal "an oil painting of an old man". We also have “a photo of a dog” and “'a man wearing a hat”, and “a photo of the amalfi coast” and “a lithograph of a skull”
In this part we'll implement Factorized Diffusion and create hybrid images. To do this, we sample at a high frequency for one prompt and a low frequency for the other. Below we have “a lithograph of waterfalls” and “a lithograph of a skull”, “a photo of the amalfi coast” and “an oil painting of a snowy mountain village”, and finally "a photo of a dog" and “an oil painting of an old man”
TODO bells and whistles
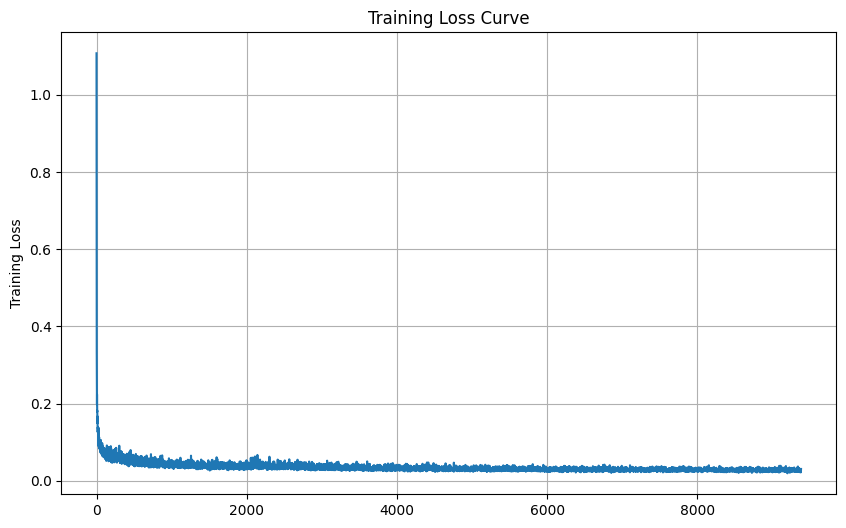
The second and final part is about training a brand new diffusion model on the MNIST dataset.
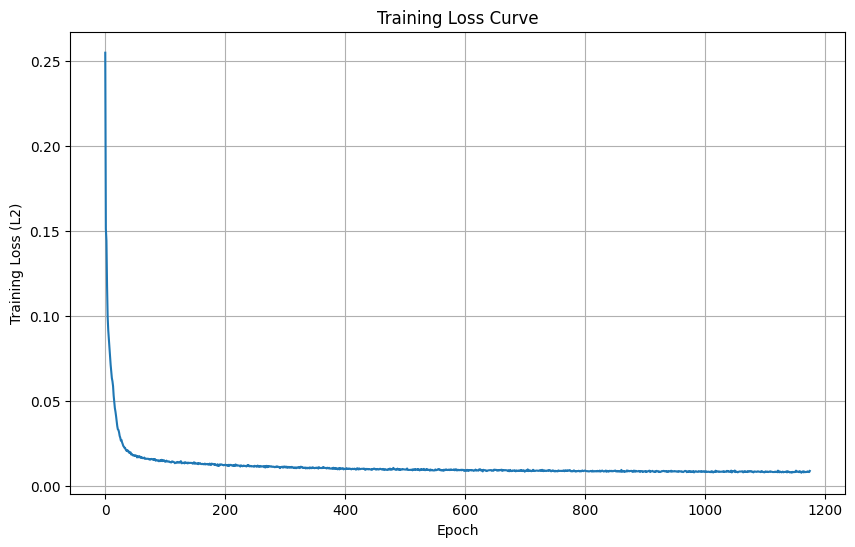
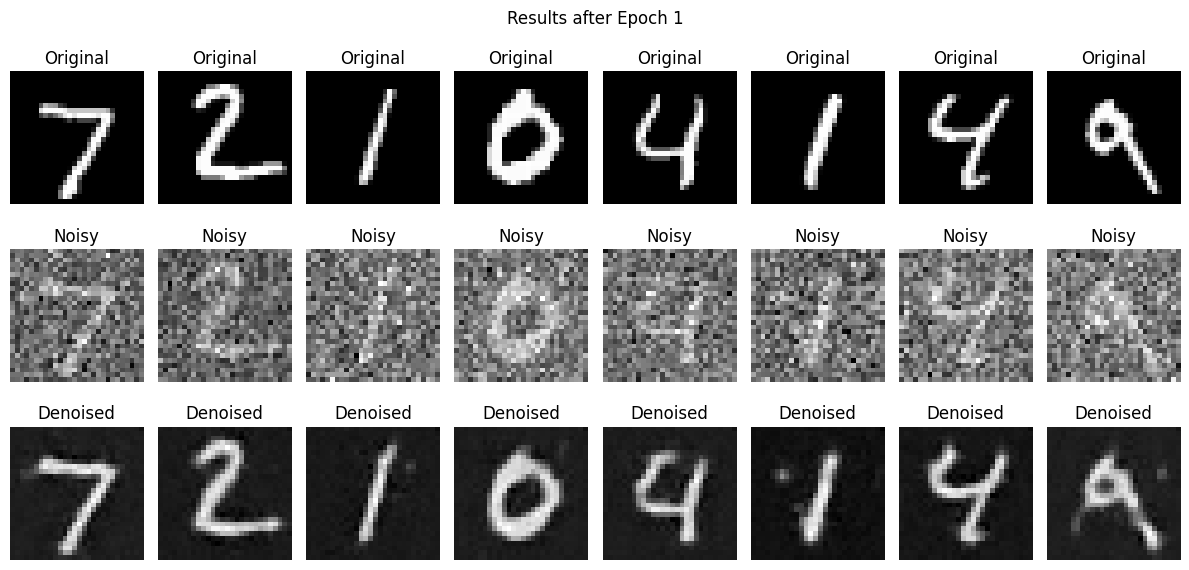
To start, a one-step denoiser was built. This takes in a noisy image, and aims to reduce the L2 loss between the model’s correction of it and the original image.
Loss
Epoch 1
Epoch 5
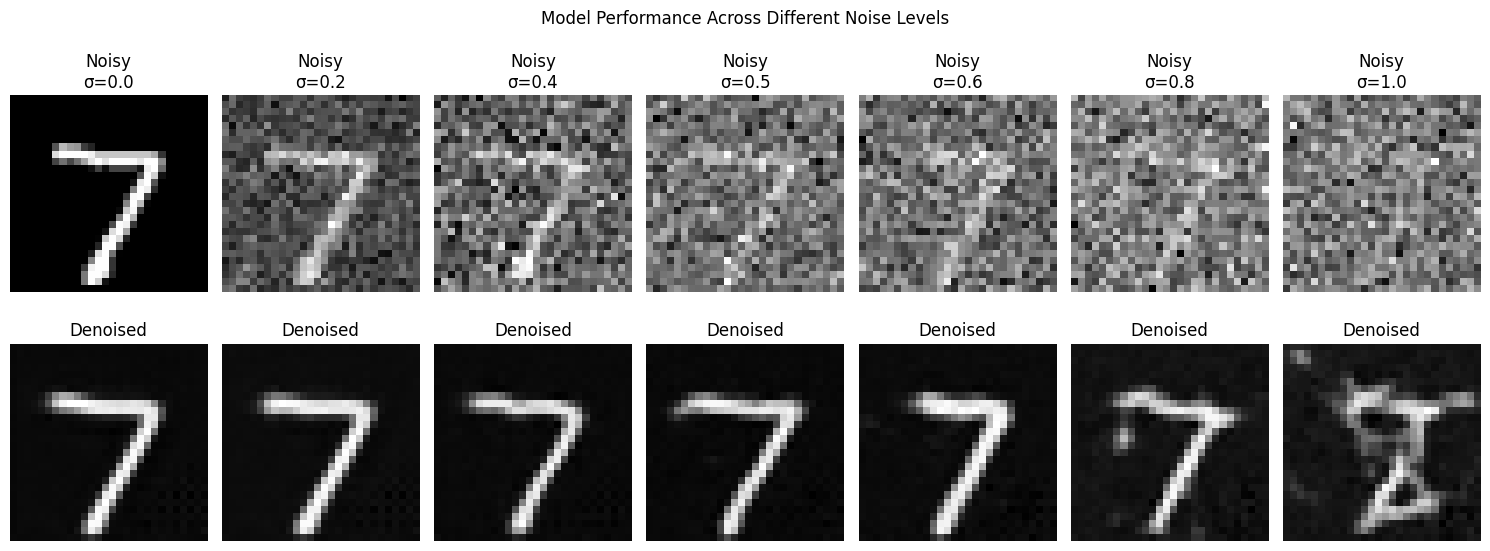
Sample results on the test set with out-of-distribution noise levels after the model is trained.
Loss
Epoch 1
Epoch 20
Loss
Epoch 5
Epoch 20